2025年1月第3周AI资讯
今天为大家总结近一周的AI资讯:
Kinetix推出了革新性的character motion control技术,让用户能够精确控制3D角色动作。该技术采用了先进的动作捕捉和迁移算法,只需上传样本视频并添加相应的提示词,即可将任意动作精确迁移到指定角色中。系统支持从简单动作到复杂舞蹈的全方位动作控制,还可以实时调节角色表情、动作速度、幅度和节奏,为创作者提供了前所未有的角色动画控制能力。值得注意的是,该技术不仅可以处理基础的人物动作,还能准确捕捉和重现细微的肢体语言和表情变化,使角色动画更加生动自然。Kinetix拥有世界领先的3D动画数据库,包含数百万个经过专业团队精心筛选的高质量动作片段和数亿个3D全身姿态数据,这些海量数据可以满足从游戏开发、影视制作到虚拟现实等各类场景的专业需求。系统的人工智能算法能够智能分析和学习这些动作数据,从而实现更精准的动作控制和自然的过渡效果。

Luma重磅发布了新一代VR模型LUMARAY2,这是一次革命性的技术突破。该模型基于Luma最新研发的多模态架构,在硬件优化和算法创新的双重加持下,计算能力较第一代提升了整整10倍。通过深度学习和计算机视觉技术的结合,LUMARAY2能够生成极其连贯流畅的动作序列和超乎想象的细节表现。在动作模拟方面,该模型展现出卓越的真实世界物理规律理解能力,能够精确还原画面中的细微动作效果,其生成的视频画面质量已经可以与专业拍摄的实景视频相媲美。VR模型不仅专注于基础视频生成,还在特效制作领域展现出强大实力,能够生成各类高品质的电影特效,从爆炸效果到自然现象的模拟都达到了极高水准。在人物表现方面,模型对人类行为模式和面部表情的理解近乎完美,能够准确捕捉和重现人物的细微情感变化。得益于其创新的多模态转换器架构,视频生成速度实现了质的飞跃,仅需10秒即可完成生成,且支持生成最长达1分钟的连续视频内容,极大提升了创作效率。目前该模型已经在Dream machine平台正式上线,支持多种艺术风格创作,为创作者提供了丰富的创作可能性。
Minimax最新推出的文本转音频技术hailuo Audio HD,代表了语音合成领域的重大突破。该技术仅需10秒的音频样本即可实现对任意语音的精确克隆,这在业界尚属首创。系统配备了Minimax自主研发的智能情感识别和重现系统,能够深度分析原始音频中的情感特征,并在合成音频中完美重现这些细腻的情感变化。T2A-01-HD模型经过大规模语音数据训练,目前已经内置超过300种精心调校的预设语音,并支持包括英语、中文、日语、法语等17种主流语言,以及粤语、四川话等多种地方方言的音频合成。用户可以根据需求灵活调整音调参数、语速快慢和情感语调的强弱,同时还可以添加混响、均衡器等专业级音效,最终输出媲美专业录音室的高品质音频作品。系统还支持批量处理和实时预览功能,大大提升了音频制作的效率。
Krea最新发布的图像转3D功能标志着3D内容创作进入了新纪元。该功能采用先进的深度估计算法,能够准确分析二维图像中的深度信息和空间关系,将用户上传的任何图像素材智能转换为具有真实感的3D图形模型。系统不仅支持基础的3D转换,还提供了丰富的后期调整工具,用户可以精确控制模型的方向、位置、比例和材质属性。这项突破性的功能已经完美集成到Carrier的实时绘图工具中,且令人惊喜的是,目前对所有用户完全免费开放。用户只需登录到canvas平台,上传所需素材,通过简单的右键操作选择convert to 3D选项,即可开始创作。系统的智能算法可以精确控制和调整图像中各个物体的空间位置关系,极大简化了3D场景构建的复杂度。此外,该功能还支持多层级编辑和实时预览,确保创作过程的流畅性和效果的精确性。
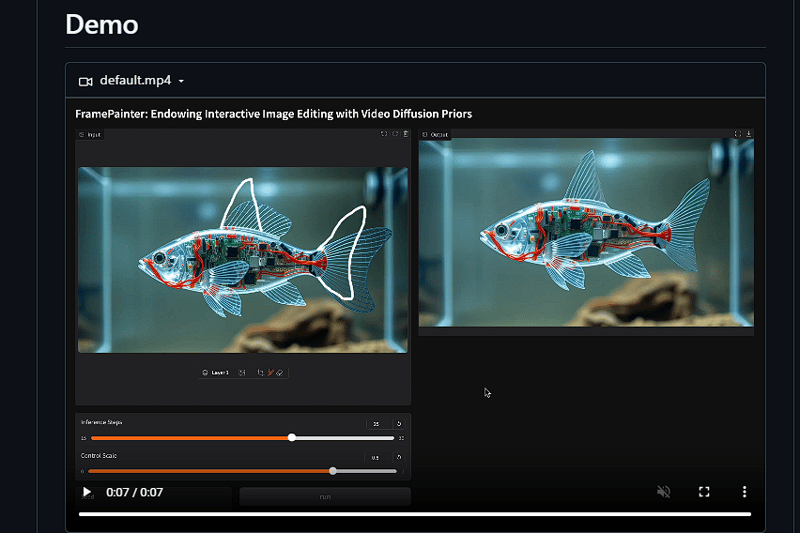
Frame Painter是一款革命性的AI辅助图像编辑工具,它彻底改变了传统的图像编辑方式。该工具的核心创新在于其直观的交互方式,用户只需通过鼠标在参考图像上勾勒简单的线条轮廓,系统就能智能理解用户的编辑意图,并生成符合预期的图像效果。这项技术采用了先进的图像理解和生成算法,能够准确识别用户的编辑意图,并在保持原始图像整体结构和风格的前提下,实现对细节的精确调整和优化。系统支持多层次的细节控制,从大范围的构图调整到微小的纹理细节都能精确把握。虽然目前该工具的源代码尚未对外开放,但其演示效果已经展现出强大的创作潜力,预计将在未来对图像编辑领域产生重大影响。
Runway重磅推出的新一代图像生成模型Frames,被业界普遍认为将成为该公司迄今为止最先进的图像生成技术。该模型在图像生成领域实现了多个突破,首先是在风格控制方面达到了前所未有的精确度,创作者可以通过简单的文本描述精确控制生成图像的艺术风格、色彩氛围和细节特征。其次,模型在视觉保真度方面也取得了显著进展,能够生成极其逼真的细节效果,无论是物体的材质表现还是光影效果都达到了极高水准。从公布的样本作品来看,Frames模型在创意图像生成方面表现出色,能够准确理解和执行复杂的创作需求,生成的图像既保持了高度的艺术性,又具备极强的现实感。特别值得一提的是,该模型在文本渲染方面也实现了重大突破,能够完美处理各种字体样式和版式设计需求。尽管Runway尚未公布具体的发布时间表,但业界普遍认为这将是今年图像生成领域最值得期待的技术突破之一。
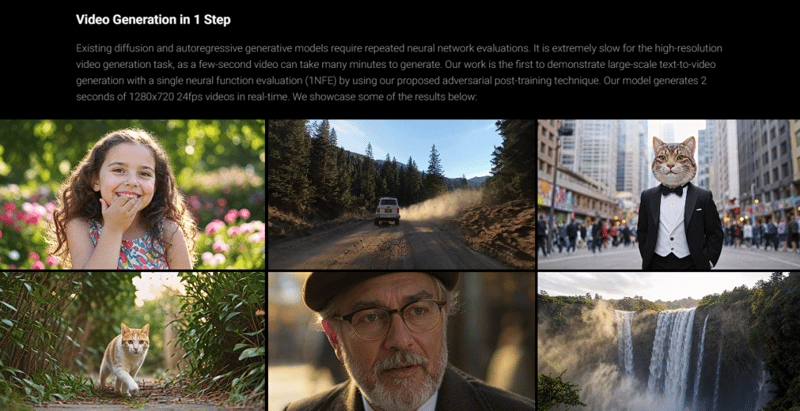
字节跳动最新推出的seaweed-apt视频生成架构代表了短视频生成技术的重大突破。这套全新的架构通过创新的算法设计和优化,实现了极快的视频生成速度,仅需一步迭代就能生成2秒钟720p分辨率的高质量视频内容。与目前主流的架构相比,seaweed-apt的技术在保证视频质量的同时,显著提升了生成效率,这对于实时视频生成和直播应用具有重要意义。系统采用了先进的神经网络架构,能够准确理解场景语义和运动规律,生成的视频在画面连贯性和细节表现上都达到了很高水准。值得注意的是,该技术还具备强大的图像生成能力,通过同样简洁的一步操作即可生成1024分辨率的高清图像,这种双模态能力的结合为创作者提供了更大的创作空间。系统还支持多种风格迁移和特效处理功能,能够满足不同场景下的创作需求。
智谱科技发布的新一代GLM实时多模态模型代表了人工智能技术的重要进展。这款模型采用了创新的多模态融合架构,不仅实现了实时视频理解和语音互动的完美结合,还突破性地加入了歌声合成功能。系统的视频理解模块采用了先进的计算机视觉算法,能够实时分析和理解视频内容的语义信息,准确识别场景、物体和人物动作。语音互动模块则通过深度学习技术实现了自然流畅的人机对话,支持多种语言和方言的实时识别和合成。特别值得一提的是,模型创新性地实现了2分钟的上下文记忆能力,这意味着系统可以在较长的时间跨度内保持对话的连贯性和上下文理解能力。在歌声合成方面,模型能够准确把握音高、节奏和情感特征,生成自然动听的歌声。这些功能的有机结合,为人机交互和内容创作开辟了全新的可能性。