12月第一周AI资讯
今天详细介绍一下近一周人工智能领域的重磅新闻:
1. Generative Omnimatte:革新视频编辑的智能技术

Google DeepMind近日推出的Generative Omnimatte技术,展示了人工智能在视频编辑领域的巨大潜力。该技术能够将视频中的不同元素(如人物、物体、背景等)分解成多个透明图层,极大地方便了后期编辑。用户可以单独处理每个图层,实现精细化的编辑和创意操作。例如,通过这一技术,用户可以移除视频中的某些物体、改变物体的运动轨迹,或者替换背景,所有这些操作都能保持视频其他元素的不变。
Generative Omnimatte采用自我学习的模型,通过对视频中的物体和环境进行深度理解,生成精确的分层效果。这不仅提升了编辑效率,还带来了前所未有的创作自由度。未来,用户甚至可以利用该技术进行创意视频的合成,将视频中的人物动作转化为线条轮廓,再进行特效和背景的替换。虽然这项技术目前仅发布了论文,并且仍需要进一步的优化,但其突破性的成果无疑为视频制作和编辑开辟了新的可能性。
2. 可玲虚拟试穿:AI助力在线购物新体验
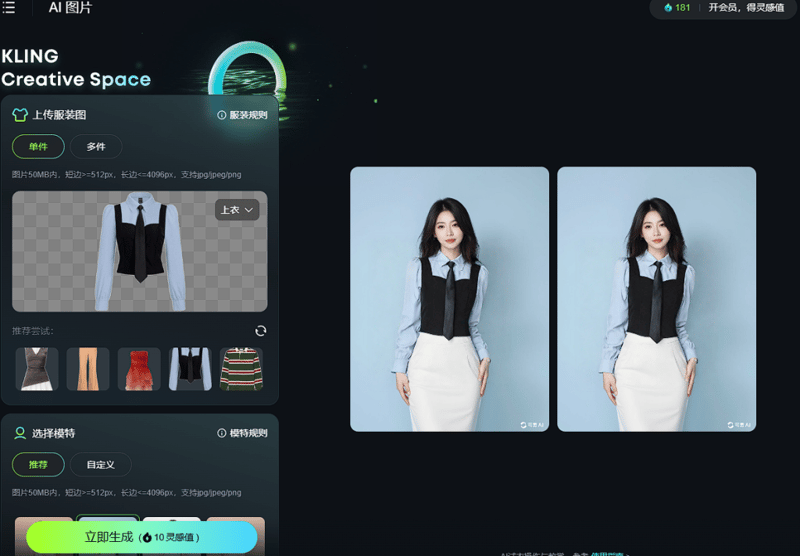
本周末,知名AI平台可玲推出了全新的AI Trion虚拟试穿功能,让用户在家中也能体验到试穿服装的乐趣。该功能利用深度学习技术生成超真实的虚拟试穿效果,用户只需上传一张服装样本并选择一个模特,即可合成一组虚拟试穿图像。如果用户希望将静态图像动态化,还可以通过可玲的图像转视频功能,将静态试穿效果转化为动态视频,进一步增强沉浸感。
可玲的虚拟试穿支持多种服装类型,包括上装、连衣裙、套装等。用户可以根据自己的需求选择不同性别和年龄的模特,设置生成图像的数量和质量。免费用户每次可以生成两张试穿图像,而高级用户则可以享受更高质量的图像生成和视频转换服务。此外,可玲还允许用户通过自定义模型上传特定的服装和模特,生成更为精确的效果图,并将其转化为5秒钟的视频片段,免费用户也能体验到这一功能。
3. CAT4D:多视角视频转换技术带来沉浸式体验
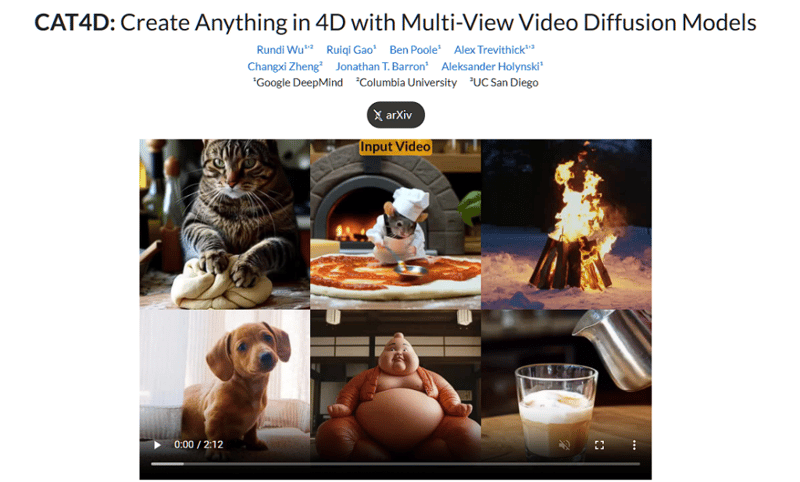
Google DeepMind推出的CAT 4D项目再次展示了人工智能在视频领域的创新能力。CAT 4D利用多视角视频扩散模型,将传统的视频转化为动态的3D场景,从而让观众能够从多个视角进行观看,提供更为沉浸式的视觉体验。这项技术不仅能够实时查看不同视角下的视频,还能生成带有多种视角的3D模型,用户可以随时冻结模型,从不同的角度查看视频内容。
目前,CAT 4D仍处于研究阶段,尚未全面推广应用。然而,随着技术的成熟,它将为电影制作、视频创作和虚拟现实(VR)领域带来革命性的变化,为内容创作者和观众提供全新的体验方式。
4. 纳米搜索:AI驱动的多模态创作引擎
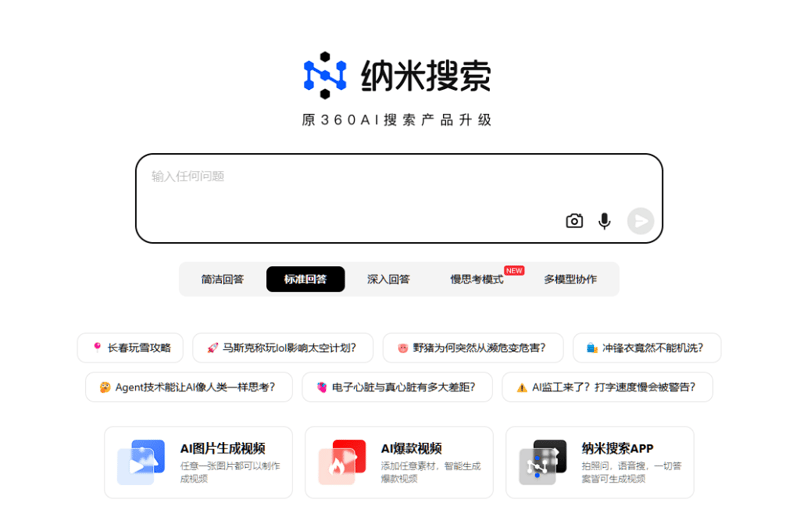
周鸿祎宣布推出一款名为“纳米搜索”的多模态创作引擎,旨在打破传统搜索引擎和创作工具的界限,提供全新的创作体验。纳米搜索能够调用文芯模型生成内容,并通过豆包模型进行内容总结,支持多模型协作,生成文本后还可以自动生成思维导图,帮助用户更好地理解内容。
该引擎不仅可以通过文本生成视频,还能选择适合的数字人主播来呈现内容。用户在生成文本的同时,可以根据视频的风格、持续时长等要求进行调整,最终将其转化为完整的视频。纳米搜索目前已在网页端和手机端推出,且完全免费,给广大用户带来了方便快捷的创作工具。
5. Autoglm升级版:跨平台智能助手
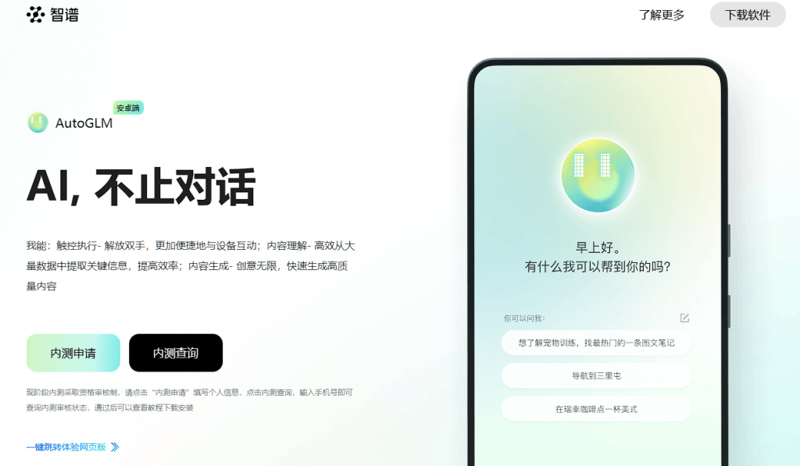
智普公司在近期发布了Autoglm的升级版,为用户带来了更多跨平台操作的能力。升级后的Autoglm能够支持超过50步的复杂任务,并可以跨APP操作,增加了对多个主流应用程序的支持。例如,用户可以通过语音指令要求Autoglm查询互联网信息,或者发布微博等社交媒体内容。此外,Web端的Autoglm支持知乎、百度、微博等多个网站的跨站点操作。
基于视觉模型,Autoglm让用户可以通过语音命令操控电脑,大大提升了工作效率。目前,Autoglm的安卓应用程序已经开放下载,用户也可以通过安装Chrome或其他浏览器插件来体验该工具,进行语音控制和操作。
6. Sana模型:秒生成4K高清图像
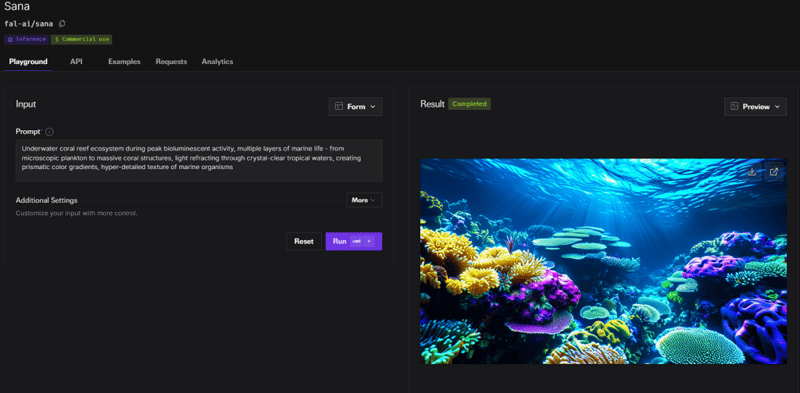
英伟达近日推出了Sana模型,这项技术能够在1秒钟内生成高质量的4K壁纸。用户只需输入提示词,Sana模型便能迅速生成超清晰的图像,并支持用户对图像进行放大和细节处理。虽然生成的图像在分辨率上无可挑剔,但在细节的处理上与主流图像生成模型仍有一定差距,未来有望通过进一步优化提升效果。
7. ConsisID:视频生成的一致性技术
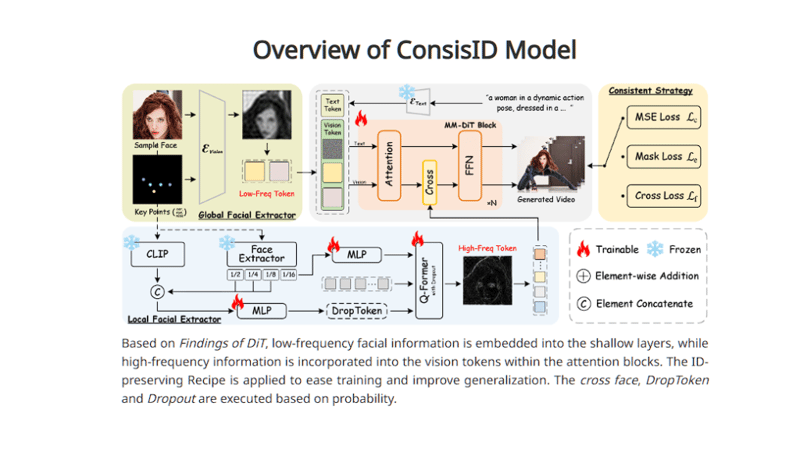
北京大学推出了ConsisID模型,专门解决视频中人物一致性的问题。只需提供一张参考图和文本提示词,ConsisID就能够生成5秒钟的视频,确保视频中人物的服装、发型、背景等元素保持一致。该技术无需微调,适用于快速生成一致性视频,目前已经在多个平台免费开放使用,供广大用户尝试和体验。