redis hyperloglog 初识
hyperloglog
前言
从官网文档可以看出 HyperLogLog 是一种估计集合基数的数据结构。作为一种概率数据结构,HyperLogLog 以完美的准确性换取高效的空间利用。
HyperLogLog的应用场景是基数统计。 基数统计顾名思义就是统计一个集合中不重复元素的个数。
Redis HyperLogLog 实现最多使用 12 KB,并提供 0.81% 的标准错误。
限制:
HyperLogLog 可以估计最多包含 18,446,744,073,709,551,616 (2^64) 个成员的集合的基数。
# 一、命令
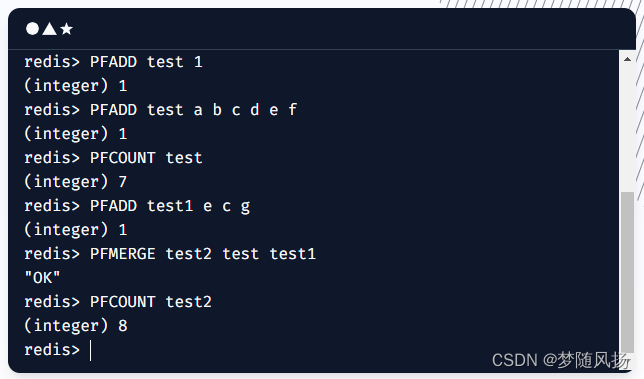
hyperloglog 的命令很简单只有三条 + 俩条测试命令 (框中的俩条命令为测试命令)
```c
PFADD 是将元素添加到hyperloglog 键 如果不存在就创建
PFADD test 1
PFADD test a b c d e f
PFCOUNT 是返回集合的唯一基数
PFCOUNT test
PFMERGE 将一个或多个HyperLogLog 合并(merge)为一个 HyperLogLog
PFMERGE test2 test test1
```
# 二、项目实战
## 1.pom 依赖:
```c
org.redisson
redisson-spring-boot-starter
3.20.1
```
## 2.添加数据:
```c
/** 添加数据 */
public void add(String testName, T item) {
RHyperLogLog hyperLogLog = redissonClient.getHyperLogLog(testName);
hyperLogLog.add(item);
}
/** 将集合数据添加到 HyperLogLog */
public void addAll(String testName, List items) {
RHyperLogLog hyperLogLog = redissonClient.getHyperLogLog(testName);
hyperLogLog.addAll(items);
}
```
## 3.合并
```c
/**
* 将 otherTestNames 的 log 合并到 testName
*
* @param testName 当前 log
* @param otherLogNames 需要合并到当前 log 的其他 logs
* @param
*/
public void merge(String testName, String... otherTestNames) {
RHyperLogLog hyperLogLog = redissonClient.getHyperLogLog(testName);
hyperLogLog.mergeWith(otherTestNames);
}
```
## 4.基数统计
```c
public long count(String testName) {
RHyperLogLog hyperLogLog = redissonClient.getHyperLogLog(testName);
return hyperLogLog.count();
}
```
## 5. 测试代码
```c
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest(classes = RedissionApplication.class)
public class HyperLogLogTest {
@Autowired
private HyperLogLogService hyperLogLogService;
@Test
public void testAdd() {
String logName = "测试";
String item = "张三";
hyperLogLogService.add(logName, item);
log.info("添加元素[{}]到 log [{}] 中。", item, logName);
}
@Test
public void testCount() {
String logName = "测试";
long count = hyperLogLogService.count(logName);
log.info("logName = {} count = {}.", logName, count);
}
@Test
public void testMerge() {
ArrayList items = new ArrayList<>();
items.add("张三");
items.add("李四");
items.add("王五");
String otherLogName = "测试2";
hyperLogLogService.addAll(otherLogName, items);
log.info("添加{}个元素到 log [{}] 中。", items.size(), otherLogName);
String logName = "测试";
hyperLogLogService.merge(logName, otherLogName);
log.info("将{}合并到{}.", otherLogName, logName);
long count = hyperLogLogService.count(logName);
log.info("合并后的count = {}.", count);
}
}
```
---
# 总结

从这里可以看出通过举例抛硬币引出redis的 hyperloglog 原理
HyperLogLog 所做的:它散列您观察到的每个新元素。散列的一部分用于索引寄存器(在我们之前的示例中,硬币+纸对。基本上我们将原始集合分成 m 个子集)。哈希的另一部分用于计算哈希中最长的前导零(我们的正面)。N+1 零游程的概率是长度 N 游程概率的一半,因此观察不同寄存器的值,它们被设置为迄今为止对给定子集观察到的最大零游程,HyperLogLog 能够提供一个非常好的近似基数。
HyperLogLog 的标准错误是 1.04/sqrt(m),其中“m”是使用的寄存器数。
Redis 使用了 16384 个寄存器,所以标准误差是 0.81%。
由于 Redis 实现中使用的散列函数具有 64 位输出,并且我们使用散列输出的 14 位来寻址我们的 16k 寄存器,我们还剩下 50 位,因此我们可以遇到的最长的零串将适合一个 6 位寄存器。这就是为什么 Redis HyperLogLog 值仅使用 12k 字节用于 16k 寄存器的原因。
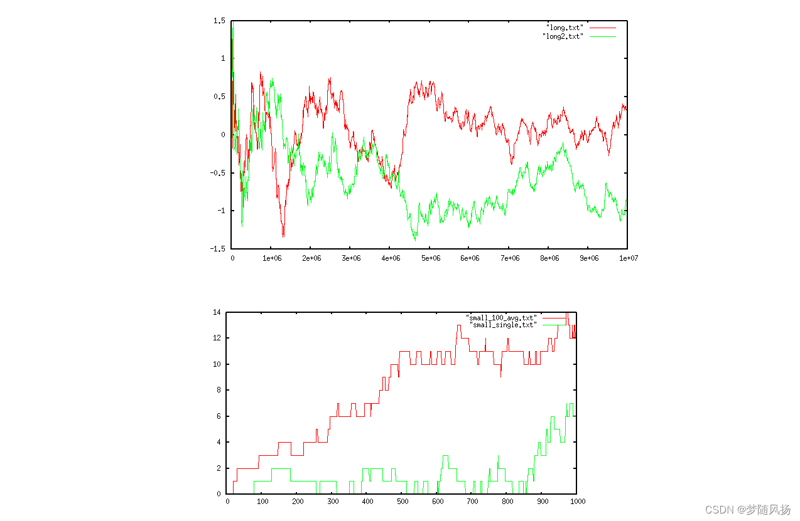
由于使用了 64 位输出函数,这是 Google 在 [2] 中提出的算法的修改之一,因此对我们可以计数的集合的基数没有实际限制。此外值得注意的是,非常小的基数的误差往往非常小。下图显示了算法针对两个不同的大型集合的运行。集合的基数显示在 x 轴中,而相对误差(百分比)显示在 y 轴中。
红线和绿线是两个完全不相关的集合的两个不同运行。它显示了随着基数的增加,错误是如何保持一致的。然而,对于更小的基数,您可以享受更小的错误:

API 由三个新命令组成:
PFADD var element element … element
PFCOUNT var
PFMERGE dst src src src … src
为了纪念 Philippe Flajolet [4],命令前缀是“PF”。
更多了解链接:
[redis hyperloglog原理 ](http://antirez.com/news/75)